TRENDING

コーディングに長けた大規模言語モデル(LLM)が登場したのは2021年ごろだ。それから5年で、競技プログラミングの問題を解けるレベルにまで成長した。なぜAIはコーディングがこれほど得意になったのか──6月10〜12日開催の「Interop Tokyo 2026」(幕張メッセ)で、LLM「tsuzumi」のコーディング能力向上を担当するNTT人間情報研究所の風戸広史さん(思考処理研究プロジェクト 主任研究員)が解説した。
tsuzumiはNTTがスクラッチで開発した国産LLM。現行の「tsuzumi 2」は一定の性能とGPU1枚で動く軽量さの両立を特徴としており、25年10月に商用提供も始まった。研究開発に約3年携わる風戸さんは、LLMのコーディング性能が進化した背景には、その発展に応じた手法の開発や研究があったと話す。
風戸さんはLLMの進化を3段階に分ける。最初の「ベースモデル」は「GPT-3」に代表される20〜21年ごろのモデルで、与えた文章の続きを生成する。プログラマーが途中までコードを書くと残りを補完する「GitHub Copilot」は、この仕組みで実現した。続く「インストラクションモデル」はChatGPTの前身「InstructGPT」から始まり、質問に対して人間にとって望ましい答えを返す。
そして24年後半から登場した、いわゆる“推論モデル”は、長考により難しい課題も細かく分解してステップごとに解く。競技プログラミング級の問題や、複数の開発工程にまたがる作業をこなせるようになり、「Claude Code」をはじめとした今日のAIエージェントサービスを支えている。
ベースモデルは、大量のテキストを与えて続きを学習させていたと風戸さん。米OpenAIの研究者はソースコードを大量に与えれば続きを書けるはずだと考え、GitHubからPythonコード159GBを集めて学習させたという。これが初代「Codex」で、Copilotの最初のバージョンに使われた。
ただし性能は現行のLLMと比すべくもなく、手作りの問題164問で構成されるベンチマーク「HumanEval」の正答率は28.8%にとどまっていた。現行のLLMは9割以上を解けるという。
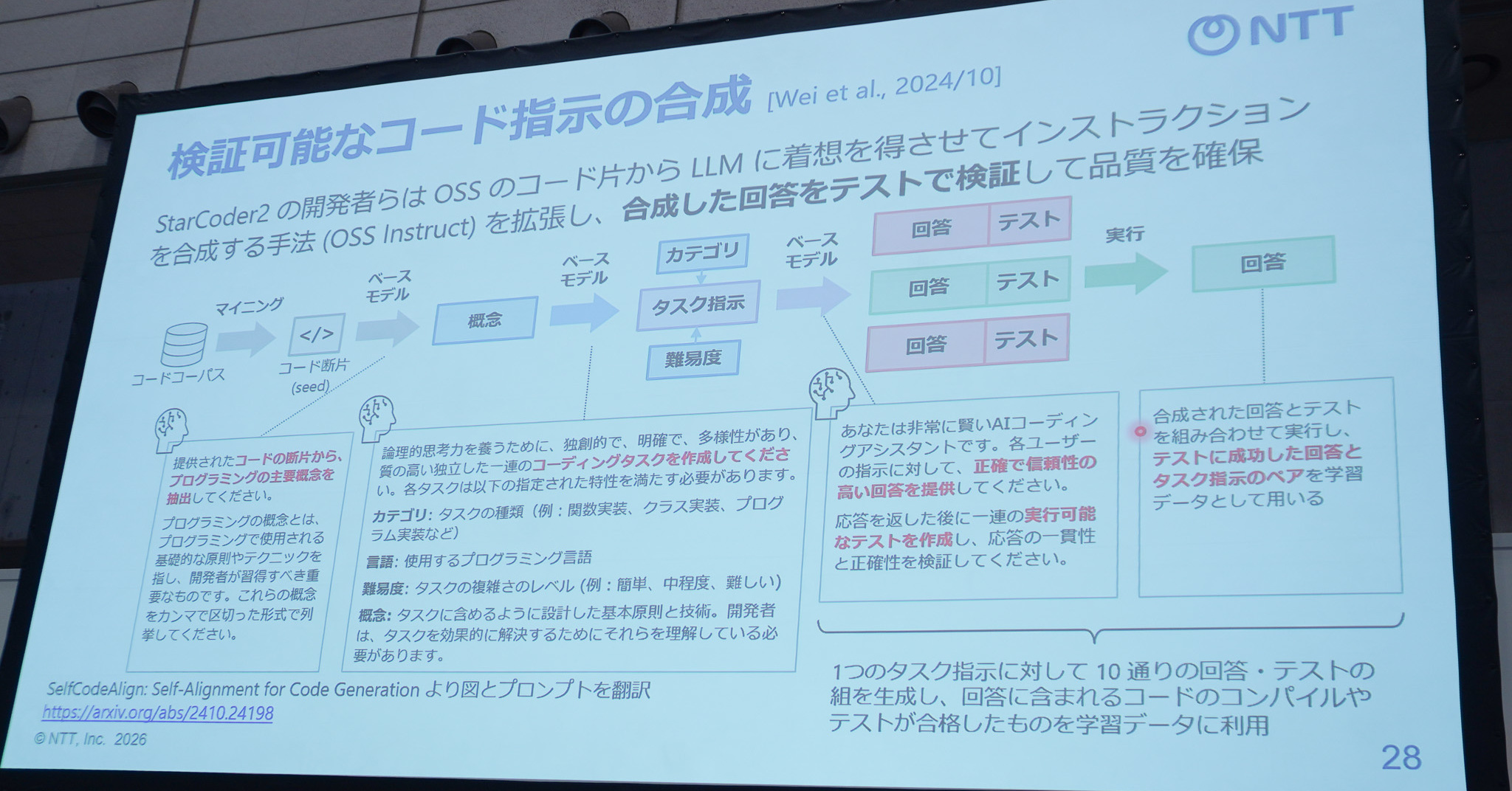
一方で、ベンチマークというルールが誕生したことで、新たに競争も始まったと風戸さん。研究者やオープンソースコミュニティーも自前のコードLLM開発に乗り出し、GitHubからコードを集めた。オープンモデル「StarCoder2」の学習用データセット「The Stack v2」は、集めたコードからライセンスに問題のないものを選び、パスワードなどの機微情報のマスキングと重複排除を施して作られ、サイズは32.1TBに達した。
ただし、収集の限界という問題も生じた。学習データ量は1年で約10倍というペースで膨らみ、Llama 3は10兆トークンに達した。GitHubのコードを集め尽くした後どうするか、という問題が浮上した。
そこで中国の研究チームが手掛けた「OpenCoder」というモデルは、集めるのではなく厳選する方法を採った。コンパイルできない、TODOやFIXMEのコメントが残っている、といった品質の低いコードを捨てていく。風戸さんは「日本酒を造るときに山田錦を削っていくように、データの品質を上げていく」と例えた。フィルタリングなしでは30点程度だったHumanEvalのスコアが、65点まで伸びたという。
一方で、捨てるのはもったいないという立場の研究もある。東京科学大学の研究グループは、別のLLMを使って品質の低いコードを書き換えてから学習に使う手法を提案した。コーディング規約に沿った書き直しなどの規則を組み合わせ、高い学習効果を得たという。
編集部注:この記事はAIを使用して作成されており、ITmedia NEWSの記事を元に、内容を変更せずにリライトしたものです。
Related posts






Latest Post



