TRENDING
AIの利用料金が、従来の月額固定型から「使った分だけ払う」従量課金へと移行しつつある。そんな中、気になるのが「日本語」という壁だ。同じ内容を伝えようとしても、言語によってAIが消費するデータ量(トークン)が異なる。日本語は英語より不利だと言われるが、実際どのモデルで、どれくらい差が出るのか。本稿では、最新の主要LLMを対象にした独自ベンチマークの結果をもとに、実態を報告する。
そもそも「トークン」とは、AIが文章を処理する際の最小単位だ。人間には同じ意味の文章でも、AIは言語や文字の種類によって、異なる数のトークンに分割して計算する。たとえば「今日は良い天気ですね」という一文は、英語の“It’s a nice day”より多くのトークンを消費する可能性がある。この「入力に対するトークン数の効率の良さ」を、本稿ではトークン効率と呼ぶ。これが悪いと、同じ作業をするにも余計なコストや処理上限の消費につながる。
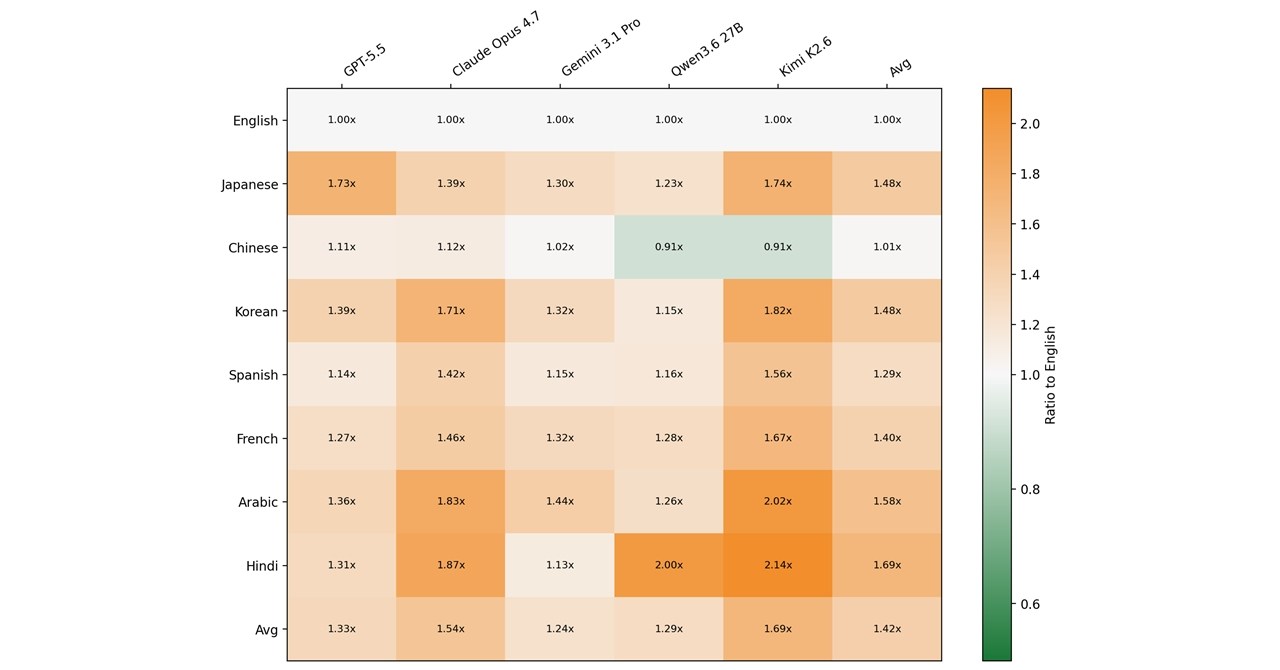
今回、GPT-5.5、Claude Opus 4.7、Gemini 3.1 Pro、Qwen3.6 27B、Kimi K2.6の5つのモデルで測定したところ、日本語の入力トークン数は、英語と比べて平均で約1.48倍に達した。つまり、日本語でAIを使うだけで、英語より約1.5倍多くのトークンを消費してしまう計算だ。これは「日本語税(Japanese Tax)」とも呼ばれる状況だが、言語別に見ると、日本語が突出して悪いわけではない。韓国語が同程度の1.48倍、アラビア語は1.58倍、ヒンディー語は1.69倍と、むしろ日本語は中位に位置する。逆に英語と中国語は非常に効率が良く、ほぼ1.0倍だった。
モデルごとの違いも顕著だ。GPT-5.5では日本語が英語比1.73倍と、今回の比較で最も低い効率を示した。一方で、Claude Opus 4.7は1.39倍と、かなり改善されている。これはAnthropicがClaude Opus 4.7で新しいトークナイザーを導入した効果が大きい。実際、従来のClaudeモデルでは日本語が1.95倍前後だったため、約3割も改善したことになる。ただし、ここで注意すべきは「英語比」の数字だけを見ていては、モデル選択を誤る可能性がある点だ。
というのも、Claude Opus 4.7は英語自体のトークン数も大幅に増えている。同じ内容の入力でも、絶対的なトークン消費量で見ると、Claude Opus 4.7は他モデルの約2.6倍に相当する。英語比の倍率が低くても、元のベースが大きければ、実際には多くのトークンを消費することになる。たとえばGPT-5.5やGemini 3.1 Proは絶対的な消費量が少なく、特にGeminiは日本語でも効率が良い。Qwen3.6 27Bも良好だ。つまり「日本語に強いモデル」を選ぶには、単に倍率だけでなく、実際にどれだけトークンを食うかという視点が欠かせない。
現場でどう使い分けるべきか。まず、日本語の長文を扱うなら、Claude Opus 4.7のトークナイザー改善は歓迎すべきだが、絶対消費量が多い点は留意したい。逆に、コストを抑えたい場合やコンテキストウィンドウを有効に使いたいなら、Gemini 3.1 ProやQwenが現実的な選択肢になる。GPT-5.5は全体的なバランスが良く、多言語対応も安定しているが、日本語に限ればやや割高だ。
何より重要なのは、従量課金が進むほど「どのモデルで、どの言語で、どれだけトークンを使うか」を意識する必要があるという点だ。無理に英語に切り替えて意図が伝わらず、再実行で余計なコストがかかるのは本末転倒。日本語で正確に考え、必要に応じて定型文や指示を英語に圧縮する――そんな使い分けが、これからの現実的な知恵になるだろう。
なお、今回の結果はあくまで2026年5月初旬時点のものであり、モデルのアップデートや料金改定によって状況は変わる。自分が実際に使う候補モデルで、同じように検証してみることをおすすめする。筆者も測定用のツールをGitHubで公開しているので、関心のある方は試してみてほしい。
編集部注:この記事はAIを使用して作成されており、ITmedia NEWSの記事を元に、内容を変更せずにリライトしたものです。
Related posts






Latest Post



