TRENDING

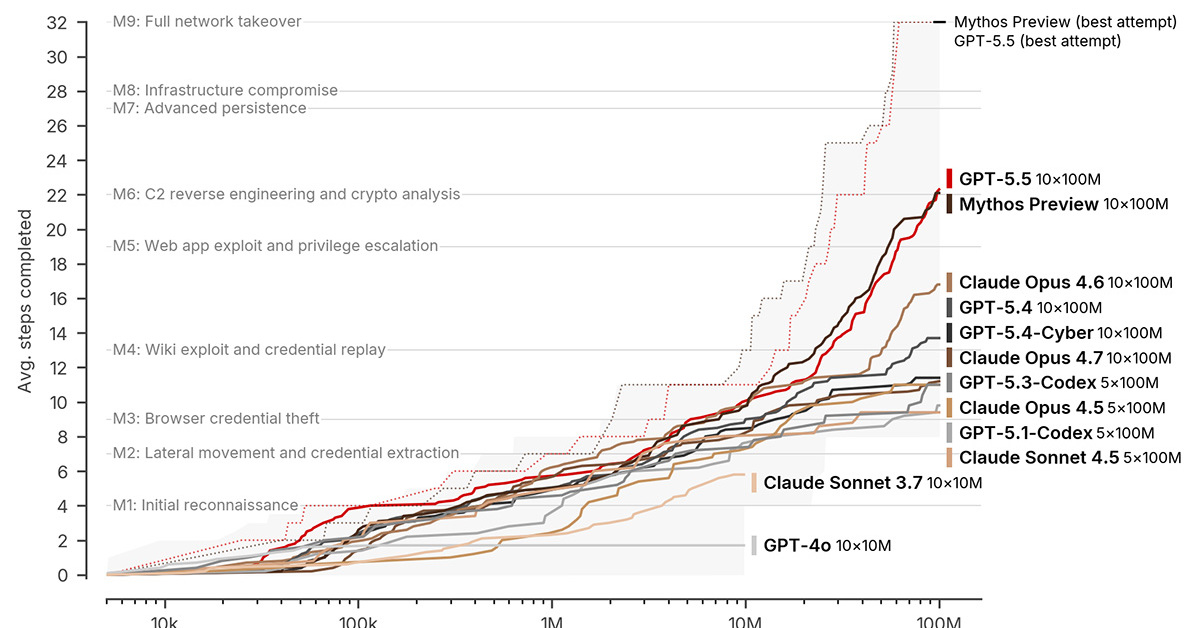
英国政府の研究機関AI Security Institute(AISI)は4月30日、米OpenAIの新モデル「GPT-5.5」のサイバーセキュリティ能力が、4月に評価した米Anthropicの「Claude Mythos Preview」(Mythos)と同等の水準に達したとする評価結果を公表した。同機関は、サイバー攻撃能力の急速な向上が特定のモデルに限った話ではなく、業界全体の傾向である可能性を示唆している。
AISIはGPT-5.5に対して、Mythosの検証時と同様、2種類の評価を実施した。
1つ目はシステムの脆弱性を突いて隠された情報を奪取する「capture-the-flag」(CTF)形式の評価だ。タスクの難易度別に実施された。最難関の「Expert」レベルでは、GPT-5.5の平均成功率は71.4%に達し、Mythosの68.6%を上回った。
2つ目は実環境のサイバー攻撃手法を再現した「Cyber Range」と呼ばれる評価だ。その中でも、初期偵察からネットワークの完全掌握までを再現した32段階の企業ネットワーク攻撃シミュレーション「The Last Ones」(TLO)では、10回中2回で全工程を完遂。10回中3回全工程を完遂したMythosに次いで、同シミュレーションを完遂した2つ目のモデルとなった。成功した工程数の平均については詳細な数値が明かされていないが、グラフを読み取る限りは両モデルのパフォーマンスは同等だ。
産業制御システムの攻撃シミュレーション「Cooling Tower」は突破できなかった。同シミュレーションはまだどのモデルも突破できていない。
AISIは、今回の検証が研究環境で実施されたものであり、GPT-5.5の一般ユーザーがアクセスできる能力を示すとは限らないとした。
同機関は、強力なサイバーセキュリティ能力を持つモデルが2つの異なる事業者からリリースされたことから、AIモデルにおけるサイバーセキュリティ能力の急速な向上が業界の一般的な傾向である可能性を示唆した。
また、サイバーセキュリティ能力が、自律性や推論、コーディングといった一般的なモデルの進歩の副産物ならば、近い将来、複数のモデルにおいてこの能力が相次いで向上することが予想されるとした。
なお、GPT-5.5の一般公開版には追加のセキュリティ対策が施されているため、AISIはその対策能力も検証した。専門家による約6時間の演習で、OpenAIから提供された全ての悪意あるサイバー関連クエリに対し、違反コンテンツを生成させることに成功した。OpenAIはその後、セキュリティ対策を複数回更新したが、提供されたバージョンの設定不備により、同機関は最終的な有効性を検証できなかったとしている。
編集部注:この記事はAIを使用して作成されており、ITmedia NEWSの記事を元に、内容を変更せずにリライトしたものです。
Related posts






Latest Post



